
|
I am a Research Scientist at Megagon Labs. Prior to Megagon, I was a PhD student in Machine Learning at the University of California Irvine, advised by Prof. Sameer Singh. My main area of interest includes Natural Language Understanding, Interpretability and Analysis of Models, and Knowledge Representation and Reasoning. |
Research Internships
- Semantic Machines at Microsoft Research, summer 2021.
- Siri Knowledge group at Apple, summer 2020.
- Allen Institute for Artificial Intelligence, summer 2019.
- Fujitsu Laboratories of America, summer 2018.
- Chinese University of Hong Kong, summer 2014.
Professional Experience
- Co-organised Explainable Graph-Based Machine Learning workshop at AKBC 2021.
- Co-organised Knowledge Bases and Multiple Modalities workshop at AKBC 2019 and 2020.
- 2021: Reviewer at NeurIPS, NAACL
- 2020: Reviewer at NeurIPS, ICLR, AAAI, EMNLP
- 2019: Reviewer at NeurIPS, ICLR, EMNLP
- 2018: Reviewer at EMNLP
- Volunteer at NeurIPS 2018 and AKBC 2020.
Preprints
- Pouya Pezeshkpour, Estevam Hruschka, "Insight-RAG: Enhancing LLMs with Insight-Driven Augmentation".
- Pouya Pezeshkpour, Estevam Hruschka, "Learning Beyond the Surface: How Far Can Continual Pre-Training with LoRA Enhance LLMs' Domain-Specific Insight Learning?".
- Vishwas Mruthyunjaya, Pouya Pezeshkpour, et al, "Rethinking Language Models as Symbolic Knowledge Graphs".
- Pouya Pezeshkpour, et al, "Distilling Large Language Models using Skill-Occupation Graph Context for HR-Related Tasks".
Conference & Journal Publications
|
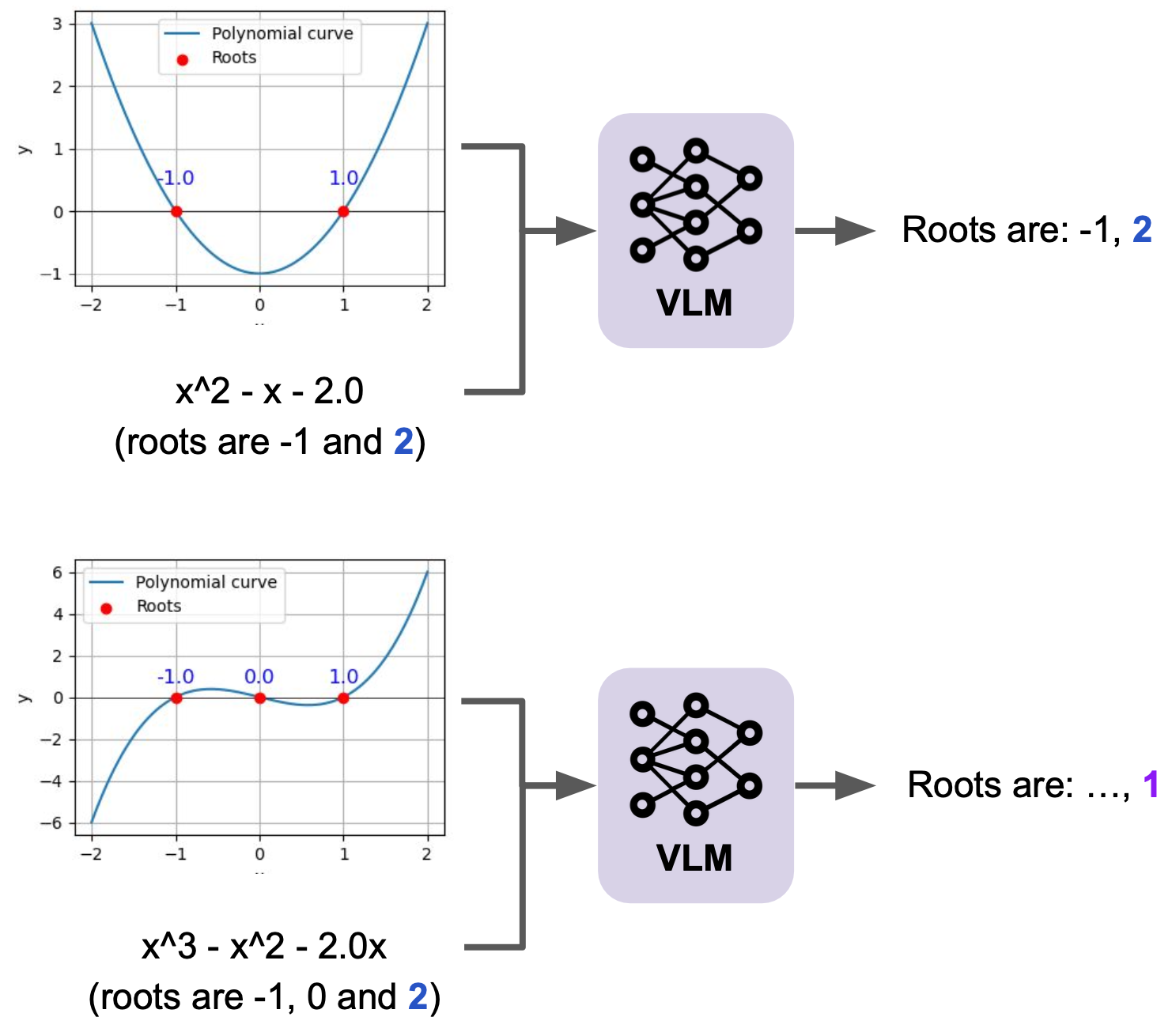
Mixed Signals: Decoding VLMs' Reasoning and Underlying Bias in Vision-Language Conflict Vision-language models (VLMs) have demonstrated impressive performance by effectively integrating visual and textual information to solve complex tasks.
However, it is not clear how these models reason over the visual and textual data together, nor how the flow of information between modalities is structured.
In this paper, we examine how VLMs reason by analyzing their biases when confronted with scenarios that present conflicting image and text cues—a common occurrence in real-world applications.
Our analysis shows that VLMs favor text in simpler queries but shift toward images as query complexity increases. This bias correlates with model scale, with the difference between the percentage of image- and text-preferred responses ranging from +56.8\% (image favored) to -74.4\% (text favored), depending on the task and model.
In addition, we explore various mitigation strategies, showing that the effectiveness of these strategies in identifying and mitigating bias varies significantly and is closely linked to the model's overall performance on the task and the specific modality in question.
|
|
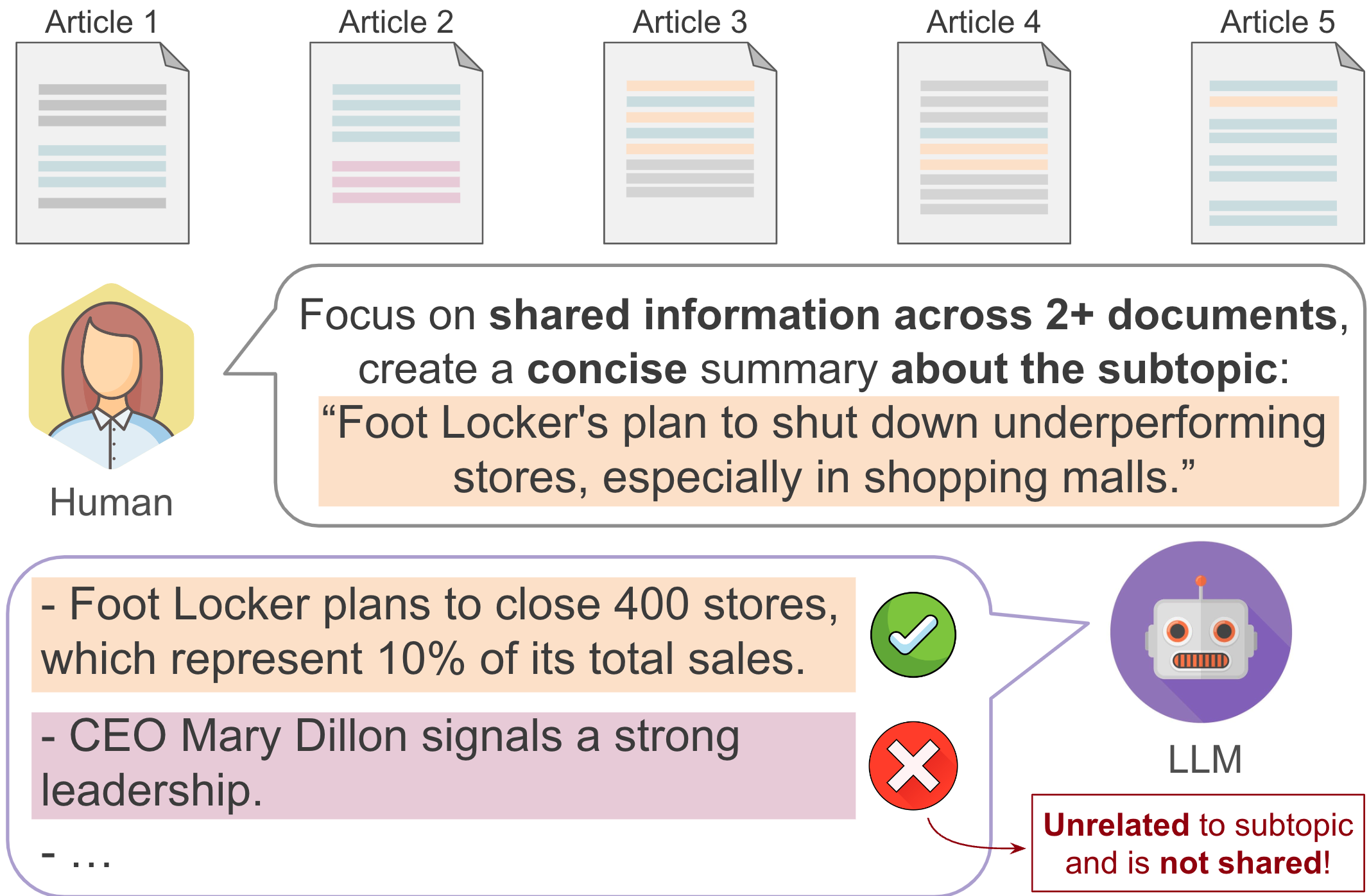
From Single to Multi: How LLMs Hallucinate in Multi-Document Summarization Although many studies have investigated and reduced hallucinations in large language models (LLMs) for single-document tasks, research on hallucination in multi-document summarization (MDS) tasks remains largely unexplored. In this work, we investigate how hallucinations manifest in LLMs when summarizing topic-specific information from multiple documents. Since no benchmarks exist for investigating hallucinations in MDS, we use existing news and conversation datasets, annotated with topic-specific insights, to create two novel multi-document benchmarks. When evaluating 5 LLMs on our benchmarks, we observe that on average, up to 75% of the content in LLM-generated summaries is hallucinated, with hallucinations more likely to occur towards the end of the summaries. Moreover, when summarizing non-existent topic-related information, gpt-3.5-turbo and GPT-4o still generate summaries about 79.35% and 44% of the time. To understand the characteristics of these hallucinations, we manually evaluate 700+ insights and find that most errors stem from either failing to follow instructions or producing overly generic insights.
Motivated by these observations, we investigate the efficacy of simple post-hoc baselines in mitigating hallucinations but find them only moderately effective.
|
|
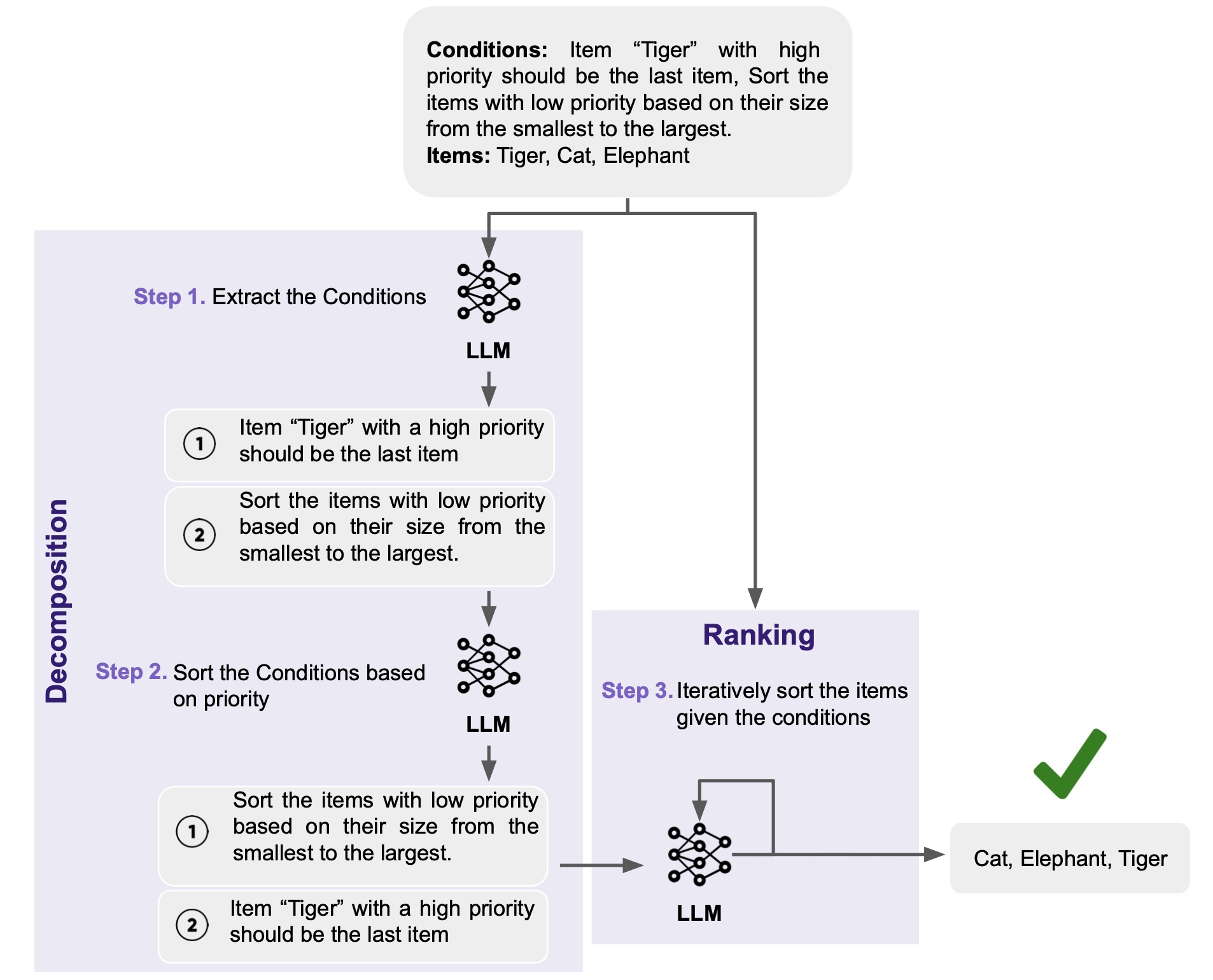
Multi-Conditional Ranking with Large Language Models Utilizing large language models (LLMs) to rank a set of items has become a common approach in recommendation and retrieval systems. Typically, these systems focus on ordering a substantial number of documents in a monotonic order based on a given query. However, real-world scenarios often present a different challenge: ranking a comparatively smaller set of items, but according to a variety of diverse and occasionally conflicting conditions. In this paper, we define and explore the task of multi-conditional ranking by introducing MCRank, a benchmark tailored for assessing multi-conditional ranking across various item types and conditions. Our analysis of LLMs using MCRank indicates a significant decrease in performance as the number and complexity of items and conditions grow. To overcome this limitation, we propose a novel decomposed reasoning method, consisting of EXtracting and Sorting the conditions, and then Iteratively Ranking the items (EXSIR). Our extensive experiments show that this decomposed reasoning method enhances LLMs' performance significantly, achieving up to a 14.4% improvement over existing LLMs.
|
|
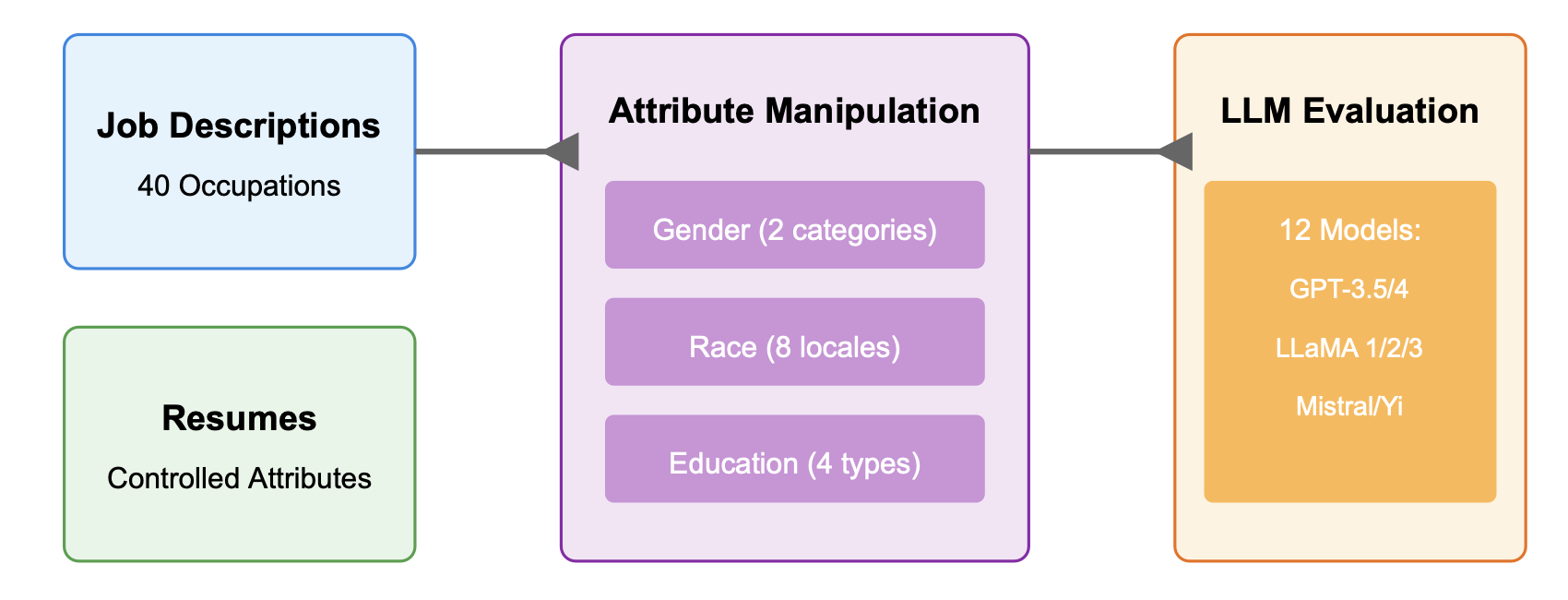
Evaluating Bias in LLMs for Job-Resume Matching: Gender, Race, and Education LLMs can automate hiring by matching job descriptions with resumes and reducing costs, but they may also reinforce biases. This study evaluates the fairness of LLMs in U.S. English-language job-resume matching by examining gender, race, and educational background. Our findings indicate that recent models have reduced biases related to explicit attributes like gender and race, yet significant implicit biases concerning educational background persist, underscoring the need for better bias mitigation strategies.
|
|
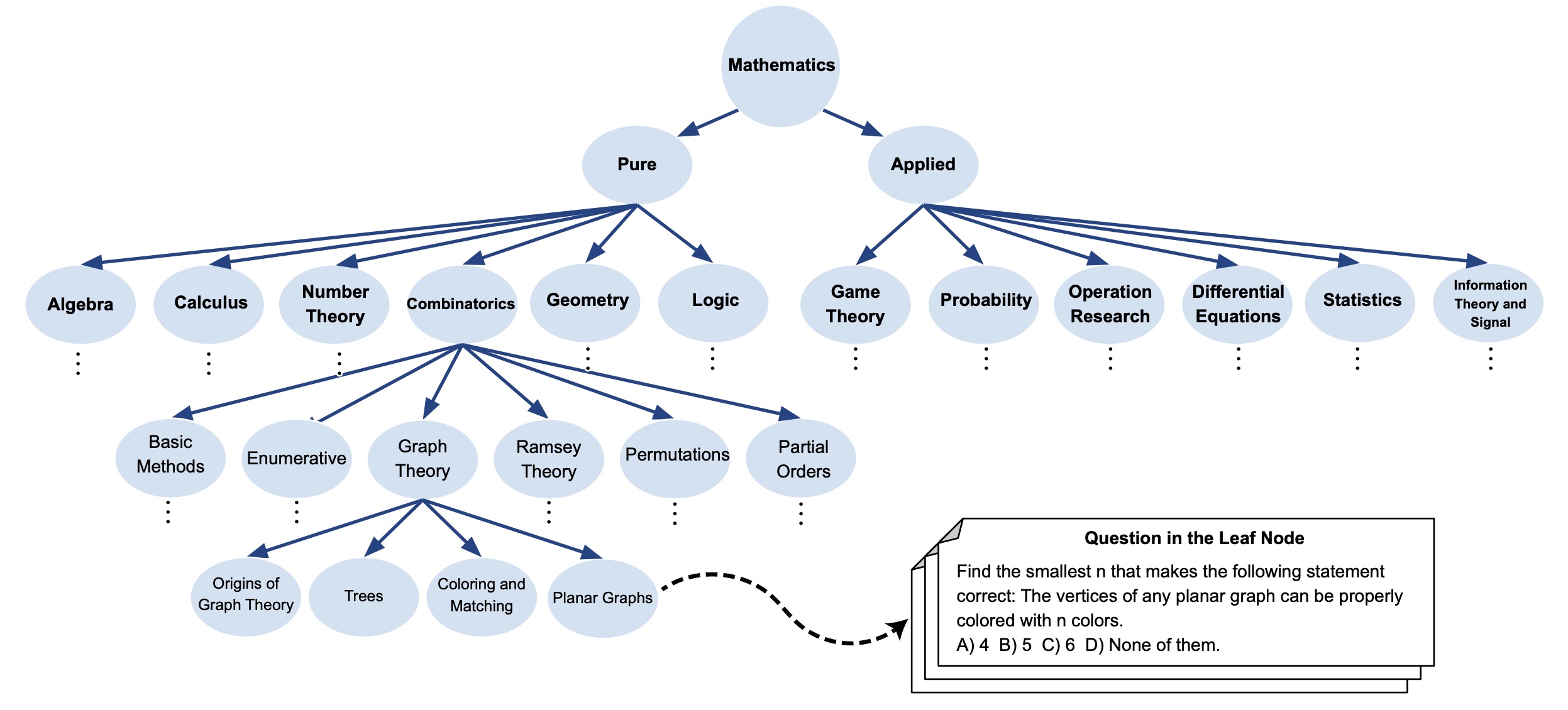
LLMs Are Not Intelligent Thinkers: Introducing Mathematical Topic Tree Benchmark for Comprehensive Evaluation of LLMs Large language models (LLMs) demonstrate impressive capabilities in mathematical reasoning. However, despite these achievements, current evaluations are mostly limited to specific mathematical topics, and it remains unclear whether LLMs are genuinely engaging in reasoning. To address these gaps, we present the Mathematical Topics Tree (MaTT) benchmark, a challenging and structured benchmark that offers 1,958 questions across a wide array of mathematical subjects, each paired with a detailed hierarchical chain of topics. Upon assessing different LLMs using the MaTT benchmark, we find that GPT-4 achieved a mere 54% accuracy in a multiple-choice scenario. Moreover, LLMs accuracy dramatically reduced by up to 24.2 percentage point when the questions were presented without providing choices. In an effort to pinpoint the reasons behind LLMs performances, we conducted a manual evaluation of the completeness and correctness of the explanations generated by GPT-4 when choices were available. Surprisingly, we find that in only 53.3% of the instances where the model provided a correct answer, the accompanying explanations were deemed complete and accurate, i.e., the model engaged in genuine reasoning.
|
|
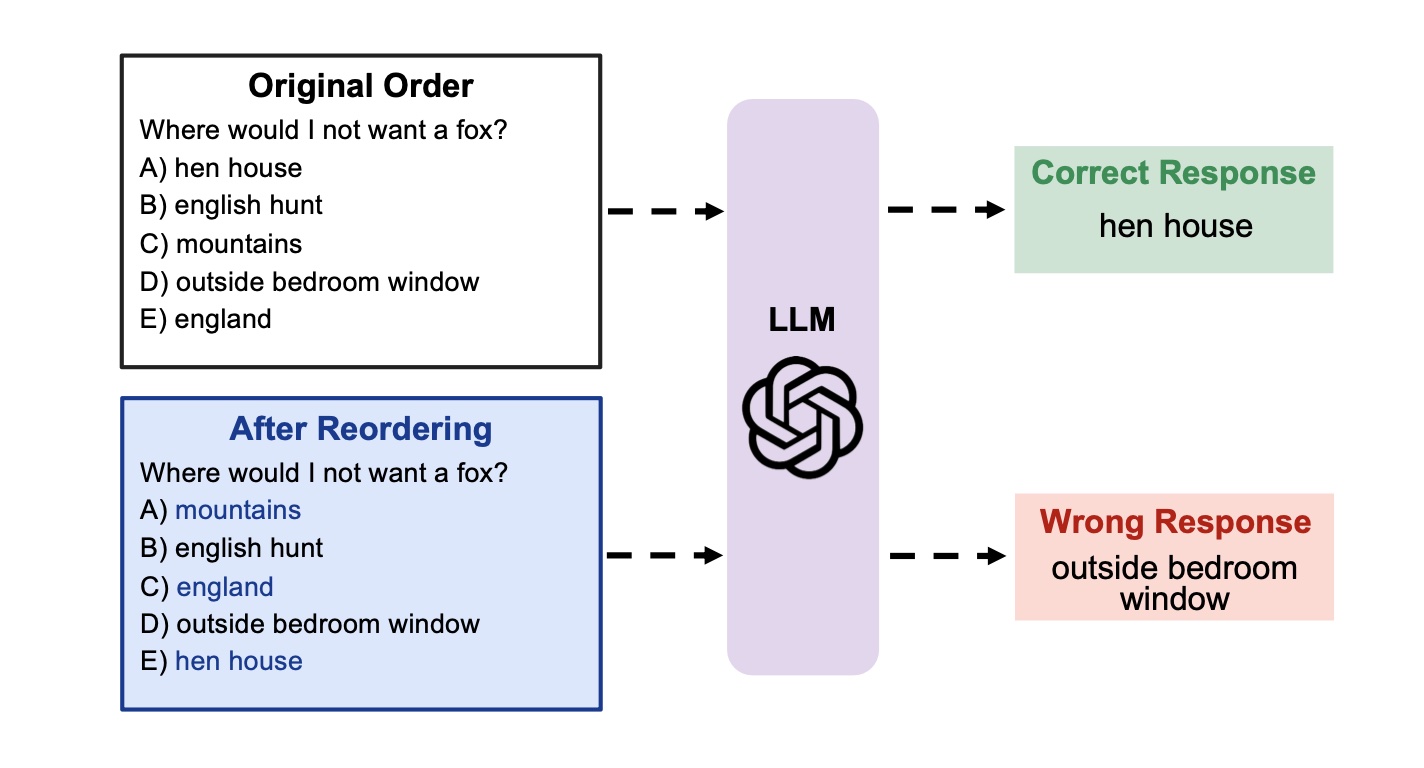
Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions Large Language Models (LLMs) have demonstrated remarkable capabilities in various NLP tasks. However, previous works have shown these models are sensitive towards prompt wording, and few-shot demonstrations and their order, posing challenges to fair assessment of these models. In this paper, we focus on LLMs robustness on the task of multiple-choice questions, commonly adopted task to study reasoning and fact-retrieving capability of LLMs. Investigating the sensitivity of LLMs towards the order of options in multiple-choice questions, we demonstrate a considerable performance gap of approximately 13% to 75% in LLMs on different benchmarks, when answer options are reordered, even when using demonstrations in
a few-shot setting. Through a detailed analysis, we conjecture that this sensitivity arises when LLMs are uncertain about the prediction between the top-2/3 choices and adopt two approaches to calibrate LLMs’ predictions, leading to up to 8 percentage points improvement across different models and benchmarks.
|
|
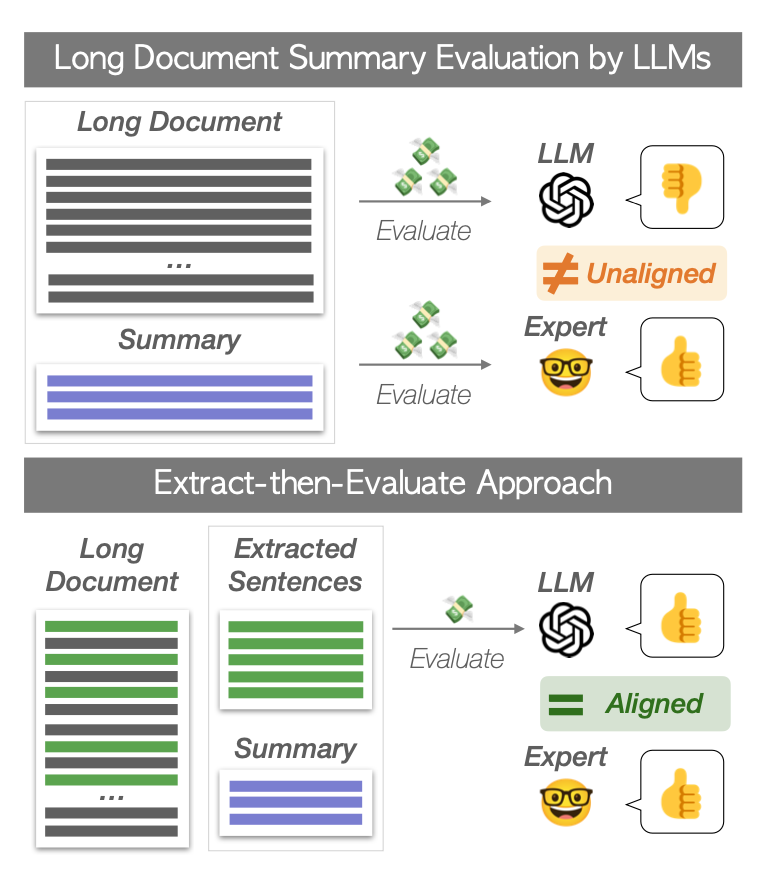
Less is More for Long Document Summary Evaluation by LLMs Large Language Models (LLMs) have shown promising performance in summary evaluation tasks, yet they face challenges such as high computational costs and the Lost-in-the-Middle problem where important information in the middle of long documents is often overlooked. To address these issues, this paper introduces a novel approach, Extract-then-Evaluate, which involves extracting key sentences from a long source document and then evaluating the summary by prompting LLMs. The results reveal that the proposed method not only significantly reduces evaluation costs but also exhibits a higher correlation with human evaluations. Furthermore, we provide practical recommendations for optimal document length and sentence extraction methods, contributing to the development of cost-effective yet more accurate methods for LLM-based text generation evaluation.
|

|
Measuring and Modifying Factual Knowledge in Large Language Models In this work, we employ information theory-based measurements to provide a framework estimating the factual knowledge contained within large language models. More specifically, we measure knowledge by analyzing the LLM’s prediction probability distribution before and after instilling the target knowledge, employing metrics such as entropy and KL-divergence. Introducing our metrics, we first assess their accuracy in comparison to previous ranking-based methods, surpassing them by over 35% in a synthetic experiment. Then, we explore two prominent methods of knowledge instillation, discovering that LLMs exhibit limitations in capturing new knowledge under specific circumstances for one of these methods. Lastly, we demonstrate the applicability of our methods in extracting unlearned and mislearned facts in LLMs through their application to in-context learning.
|

|
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models In this paper we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, with diverse topics about drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI’s GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. Findings include: model performance and calibration both improve with scale; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit “breakthrough” behavior at a critical scale often involve multiple steps; social bias typically increases with scale in ambiguous settings, but this can be improved with prompting.
|
|
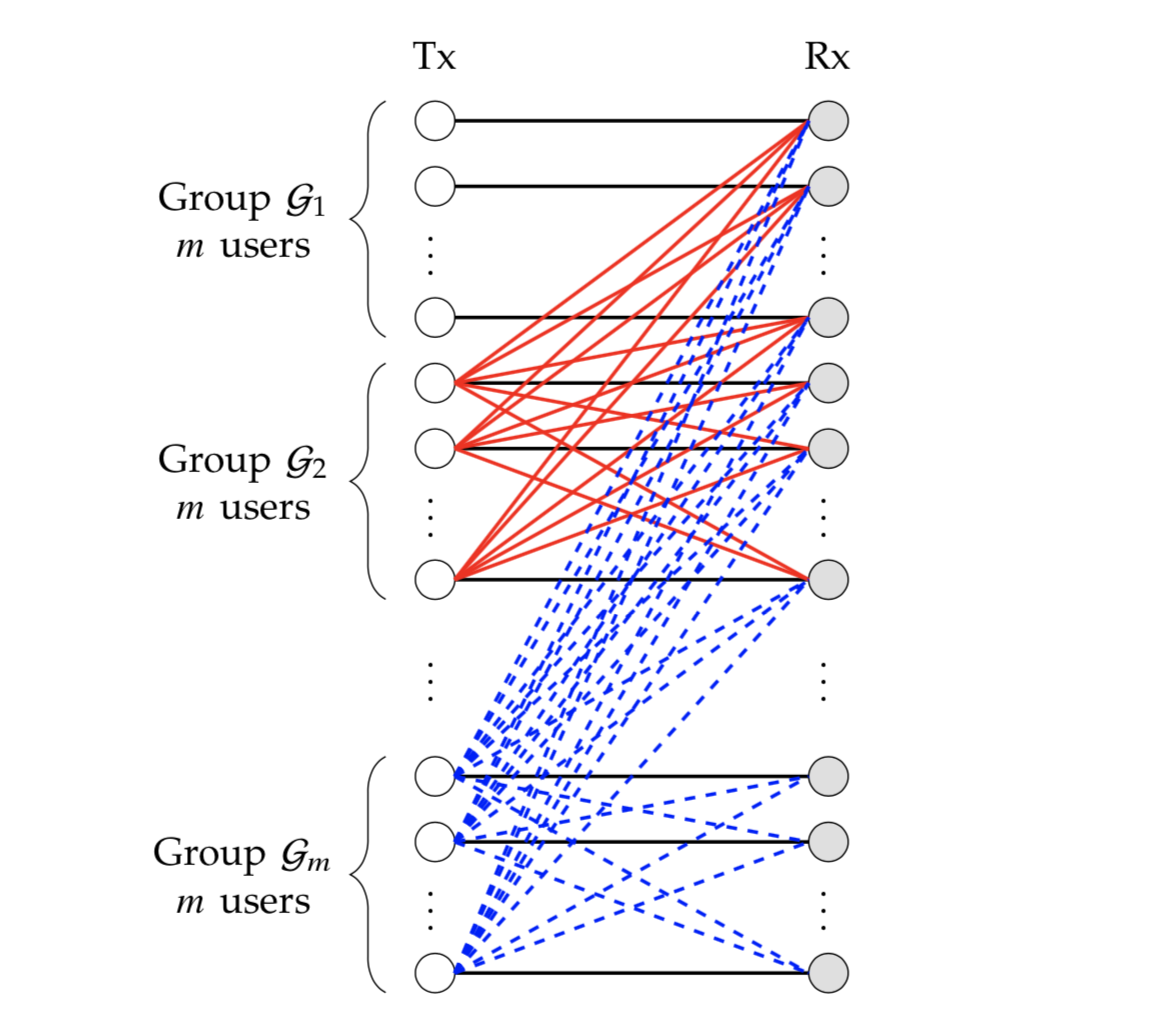
The Extremal GDoF Gain of Optimal versus Binary Power Control in 𝐾 User Interference Networks Is Θ(√k) In this paper we explicitly characterizes the extremal GDoF gain of optimal over binary power control as Θ(√k) for all 𝐾. In particular, the extremal gain is bounded between
√k and 2.5 √k for every 𝐾. For 𝐾 = 2, 3, 4, 5, 6 users, the precise extremal gain is 1, 3/2, 2, 9/4 and 41/16, respectively. Networks shown to achieve the extremal gain may be interpreted as multi-tier heterogeneous networks. It is worthwhile to note that because of their focus on asymptotic analysis, the sharp characterizations of extremal gains are valuable primarily from a theoretical perspective, and not as contradictions to the conventional w. |
|
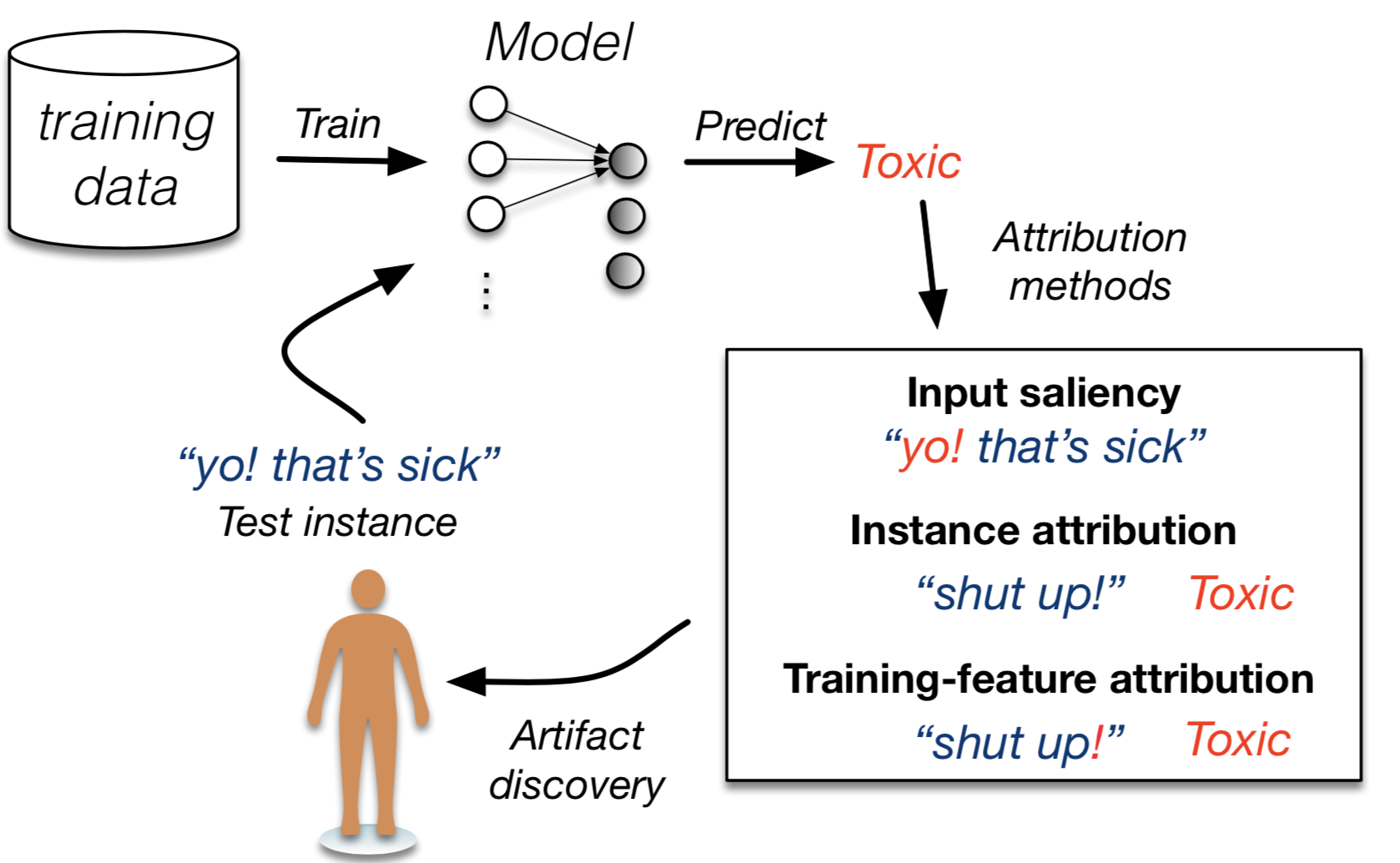
Combining Feature and Instance Attribution to Detect Artifacts In this paper we evaluate use of different attribution methods for aiding identification of training data artifacts. We propose new hybrid approaches that combine saliency maps (which highlight "important" input features) with instance attribution methods (which retrieve training samples "influential" to a given prediction). We show that this proposed training-feature attribution can be used to efficiently uncover artifacts in training data when a challenging validation set is available. We also carry out a small user study to evaluate whether these methods are useful to NLP researchers in practice, with promising results. |
|
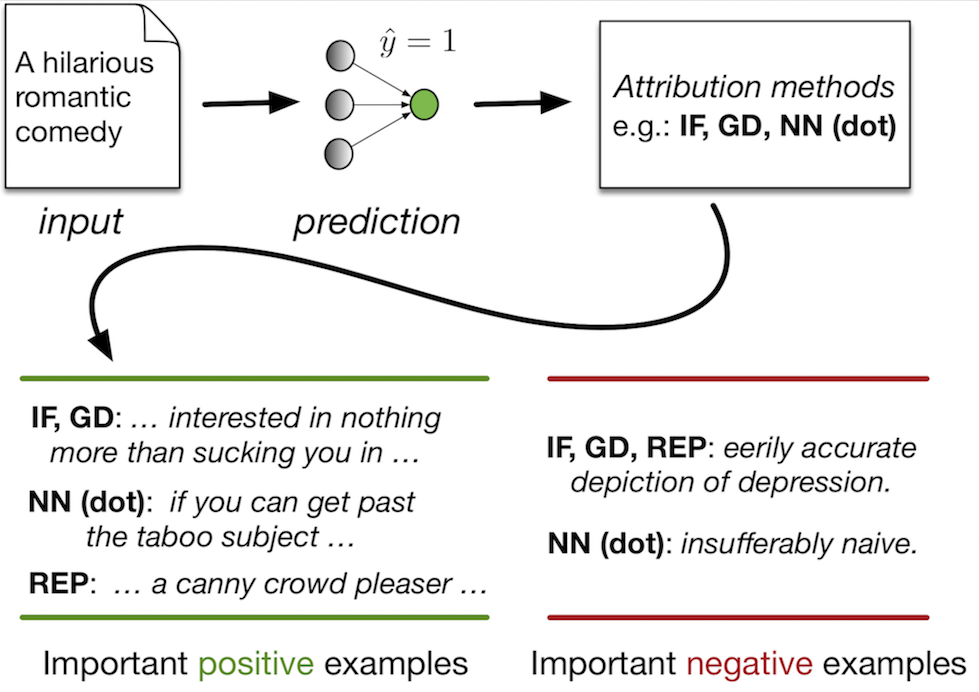
An Empirical Comparison of Instance Attribution Methods for NLP In this work we evaluate the degree to which different potential instance attribution agree with respect to the importance of training samples.
We find that simple retrieval methods yield training instances that differ from those identified via gradient-based methods (such as the IF), but that nonetheless exhibit desirable characteristics similar to more complex attribution methods. |

|
PARSINLU: A Suite of Language Understanding Challenges for Persian We introduce PARSINLU, the first benchmark in Persian language that includes a range of high-level tasks, Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5k new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi- lingual pre-trained language models on this benchmark and compare them with human performance, which provides valuable in- sights into our ability to tackle natural language understanding challenges in Persian. |
|
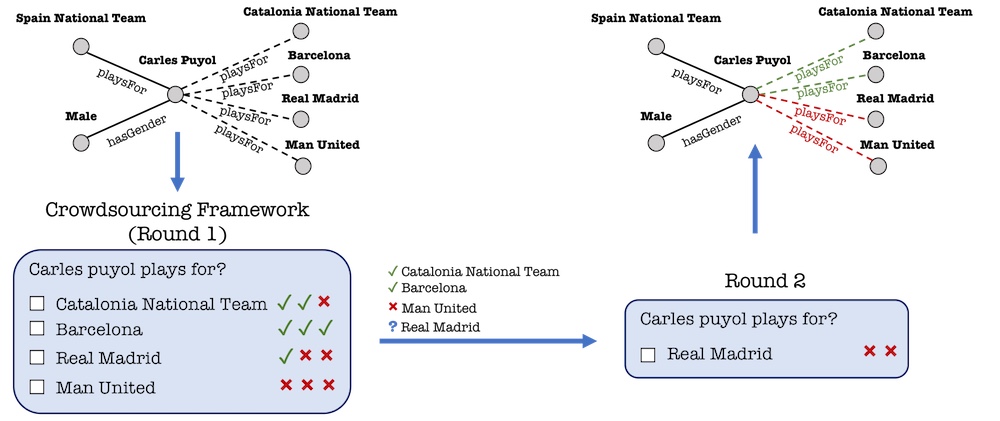
Revisiting Evaluation of Knowledge Base Completion Models In this paper, we first study the shortcomings of the evaluation metrics in knowldge graph Embeddings. More specifically, we demonstrate that these metrics 1) are unreliable for estimating calibration, 2) make strong assumptions that are often violated, and 3) do not sufficiently, and consistently, differentiate embedding methods from simple approaches and from each other. To address these issues, we provide a semi-complete KG using a randomly sampled subgraph from the test and validation data of YAGO3-10, allowing us to compute accurate triple classification accuracy on this data. |
|
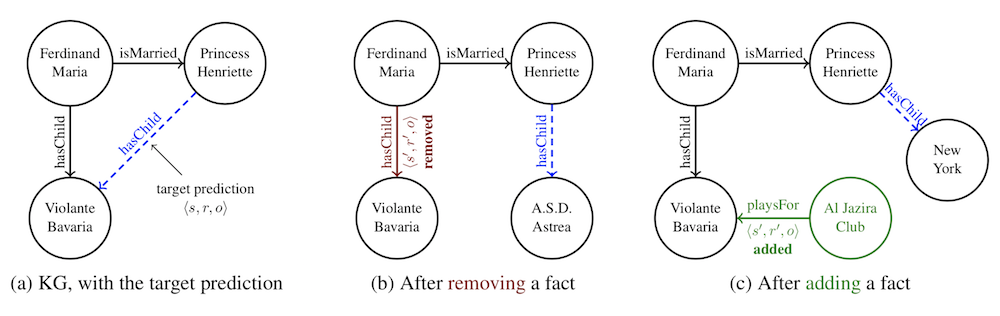
Investigating Robustness and Interpretability of Link Prediction via Adversarial Modifications In this paper, we propose adversarial modifications for link prediction models: identifying the fact to add into or remove from the knowledge graph that changes the prediction for a target fact after the model is retrained. We introduce an efficient approach to estimate the effect of such modifications by approximating the change in the embeddings when the knowledge graph changes. We use these techniques to evaluate the robustness of link prediction models (by measuring sensitivity to additional facts), study interpretability through the facts most responsible for predictions (by identifying the most influential neighbors), and detect incorrect facts in the knowledge base. |
|
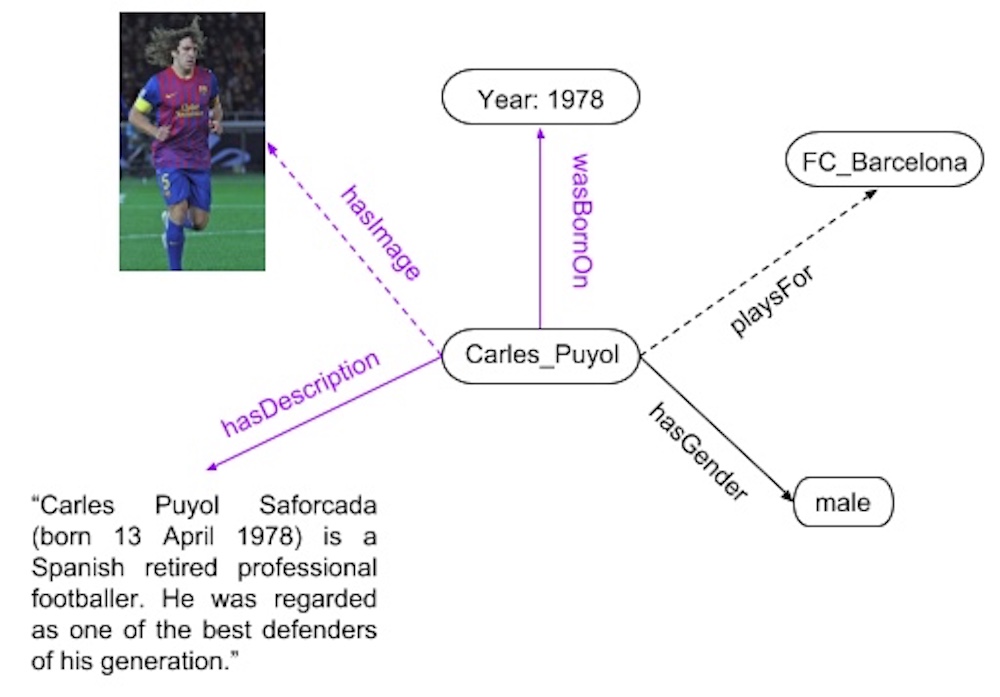
Embedding Multimodal Relational Data for Knowledge Base Completion In this work, we propose multimodal knowledge base embeddings (MKBE) that use different neural encoders for this variety of observed data, and combine them with existing relational models to learn embeddings of the entities and multimodal data. Further, using these learned embedings and different neural decoders, we introduce a novel multimodal imputation model to generate missing multimodal values, like text and images, from information in the knowledge base. |
|
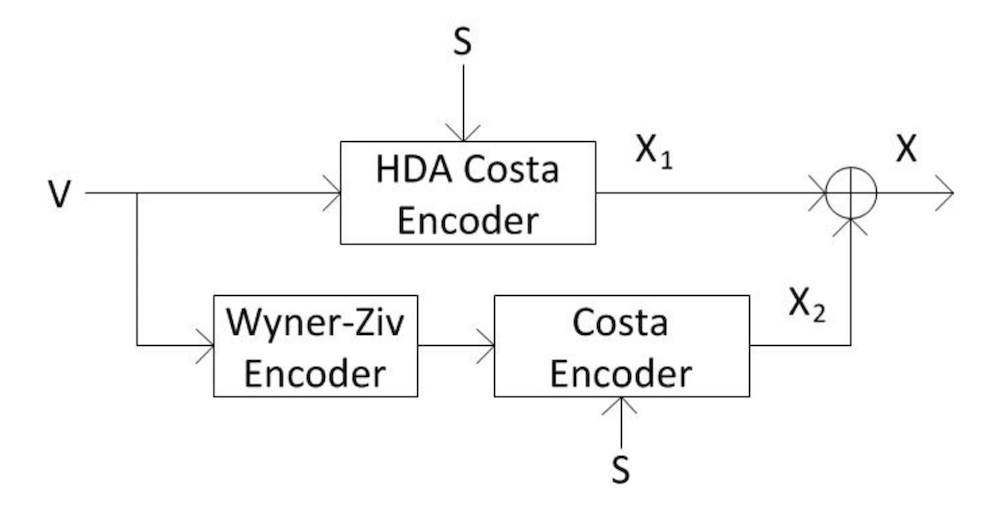
Optimal tradeoff between source and state distortions over a Gaussian channel using single and hybrid digital analog codes In this paper, the problem of transmitting an analog Gaussian source over an additive white Gaussian noise (AWGN) channel in the presence of a Gaussian interference known only at the transmitter is investigated. Our goal is to estimate both the analog source and the channel state at the receiver simultaneously. In this work, we present different transmission schemes based on joint source-channel coding. We study hybrid digital-analog (HDA) joint source-channel coding schemes and analyze the region of (mean-squared error) distortion pairs (in estimating the source and the state) that are simultaneously achievable. |
Workshop & Symposia
- Pouya Pezeshkpour, et al,"Reasoning Capacity in Multi-Agent Systems: Limitations, Challenges and Human-Centered Solutions". Compound AI Systems 2024.
- Eser Kandogan, et al,"A Blueprint Architecture of Compound AI Systems for Enterprise". Compound AI Systems 2024.
- Preethi Seshadri, Pouya Pezeshkpour, Sameer Singh,"Quantifying Social Biases Using Templates is Unreliable". The TSRML workshop at NeurIPS 2022.
- Pouya Pezeshkpour, Zhengli Zhao, Sameer Singh,"On the Utility of Active Instance Selection for Few-Shot Learning". The HAMLETS workshop at NeurIPS 2020.
- Pouya Pezeshkpour, Zhengli Zhao, Sameer Singh,"Using Data Importance for Effective Active Learning". The CVPR workshop on Visual Learning with Limited Labels (VL3), 2020.
- Pouya Pezeshkpour, Yifan Tian, Sameer Singh, "Integrating Local Structure into Knowledge Graph Embeddings". SoCal NLP Symposium 2019.
- Pouya Pezeshkpour, Ramya Malursrinivasan, Ajey Chander, "Generating User-friendly Explanations for Loan Denials using GANs". NIPS 2018 Workshop on Challenges and Opportunities for AI in Financial Services.
- Pouya Pezeshkpour, Carlos Guestrin, Sameer Singh, "Compact Factorization of Matrices Using Generalized Round-Rank". Southern California Machine Learning Symposium 2017.
Patents
- Pouya Pezeshkpour, Ramya Malursrinivasan, Ajay Chander, "USER-FRIENDLY EXPLANATION PRODUCTION USING GENERATIVE ADVERSARIAL NETWORKS". US Patent Number 20200125640, 2020.
- Pouya Pezeshkpour, Ramya Malursrinivasan, Ajey Chander, "EXPLANATIONS GENERATION WITH DIFFERENT COGNITIVE VALUES USING GENERATIVE ADVERSARIAL NETWORKS". US Patent Number 20200125975, 2020.